Volatility Forecasts (Part 6 - STES to VolGRU Relaxation Ladder)
2026-03-05
1 Introduction
Part 5 held the data and feature design fixed and asked which predictors help STES-style volatility models. This post keeps that same empirical setup and asks a different question: what happens if we change the updating mechanism itself, while still keeping the latent volatility state one-dimensional?
The starting point is the STES model from earlier in the series. The endpoint is a scalar, or one-dimensional, VolGRU: a GRU-style updating rule in which the hidden state is just one number rather than a vector. The goal of the post is to show that these are not unrelated objects. STES can be written as a tightly restricted scalar GRU, and once that connection is made we can study a sequence of models that removes those restrictions one by one.
That sequence is what I call the model ladder. By ladder, I just mean an ordered list of models, where each new model changes exactly one piece of the previous one. By relaxing STES, I mean allowing one part of the STES update rule to become more flexible than before. The central questions are therefore: can a constrained scalar VolGRU reproduce STES exactly, which added degrees of freedom matter empirically, and do they improve forecasting enough to justify the extra complexity?
2 GRU Primer
Because this post studies a one-dimensional VolGRU, it is clearer to write the GRU update directly in scalar form. Let h_t be the scalar hidden state and let u_t collect the observable inputs at time t. A scalar GRU uses three moving parts: an update gate z_t, a reset gate r_t, and a candidate state \tilde h_t. One convenient way to write the update is
The last line is the important one. The new state is a weighted average of the old state and the candidate state. If z_t is near zero, the model mostly keeps the old state. If z_t is near one, it moves strongly toward the candidate. The reset gate r_t affects the candidate itself by controlling how strongly the old state enters that candidate.
For volatility forecasting, this structure should already feel familiar. STES also updates a running state by blending yesterday’s forecast with today’s new information through a time-varying weight. So before fitting anything, the right conceptual question is not why bring in a GRU at all? It is how close is STES already to this scalar GRU update rule?
3 From STES to One-Dimensional GRU
Let r_t denote daily log return and define x_t = r_t^2. In the notation used earlier in the series, the STES recursion is
v_t = (1-\alpha_t) v_{t-1} + \alpha_t x_t,
with gate
\alpha_t = \sigma(\beta^\top \phi_{t-1}),
where v_t is the filtered variance state, x_t is the new squared-return observation, and \phi_{t-1} contains the lagged predictors that determine the gate. In this post, \phi_{t-1} includes the augmented feature set carried over from Part 4.
Now compare that with the scalar GRU update
h_t = (1-z_t) h_{t-1} + z_t \tilde h_t.
These two equations have the same structure: both combine an old state with a new candidate using a time-varying weight. To recover STES from the scalar GRU form, impose the following identifications and restrictions:
Set the GRU state equal to the variance state: h_t = v_t.
Set the GRU update gate equal to the STES gate: z_t = \alpha_t.
Force the GRU candidate to be the raw squared return: \tilde h_t = x_t = r_t^2.
Keep the state one-dimensional and do not give the candidate an active reset-gate role.
Under those restrictions, the GRU update collapses exactly to the STES recursion. That is the key reason the connection matters: STES is not merely inspired by a GRU-style update. It can be written as a very specific scalar GRU with most of the GRU flexibility switched off.
This also explains what relaxing STES means in the rest of the post. A relaxation is just the removal of one of those restrictions. We can first let the candidate be learned instead of fixed at r_t^2. We can then let the update gate depend on the current state as well as observable features. We can then add reset behavior. Finally, we can replace the linear candidate map with a nonlinear one. The model sequence below follows exactly that path.
4 STES-to-GRU Mapping at a Glance
The table below summarizes the scalar correspondence and shows what changes as we move from STES toward the fuller one-dimensional VolGRU specification studied in this post.
STES object
Scalar GRU interpretation
What gets relaxed later?
Variance state v_t
Hidden state h_t
The state remains one-dimensional throughout this post.
Gate \alpha_t
Update gate z_t
In M3, the gate is allowed to depend on the current state as well as observable features.
Squared return x_t=r_t^2
Candidate state \tilde h_t
In M2, the fixed candidate is replaced by a learned positive candidate.
No reset mechanism
Reset gate inactive
In M4, reset behavior is introduced.
Linear candidate restriction
Simple candidate map
In M5, the candidate becomes nonlinear.
So if you want a one-line summary of the post, it is this: start from STES, rewrite it as a constrained scalar GRU update, and then remove those constraints one at a time to see which ones actually help forecasting.
5 Data and Empirical Setup
I keep the Part 4 protocol unchanged. The sample is SPY from January 2000 through December 2023, with a fixed split at row 4000. That way the train and test windows stay constant while only the model architecture changes.
Because the target is next-day squared return, the deterministic calendar and scheduled-event features are attached to the date being forecast. A row at date t is used to predict next-day variance, so it carries the known-ahead calendar and event labels for the next trading session t+1.
Cache-only preflight
PARITY_TICKER ='SPY'PARITY_START = pd.Timestamp('2000-01-01', tz='UTC')PARITY_END = pd.Timestamp('2023-12-31', tz='UTC')PARITY_SPLIT_INDEX =4000parity_cache_key =f'{PARITY_TICKER}|adj=True'parity_cached = cache.get(parity_cache_key)if parity_cached isNoneor parity_cached.empty:raiseRuntimeError(f'Cache-only mode: no cached data found for key={parity_cache_key} in {SCRIPT_CACHE_DIR}. ''Populate cache first; this notebook does not pull live Tiingo data.' )print('Cache preflight OK:', parity_cache_key)
I will now compare an ordered sequence of models. This is what I mean by the model ladder: each rung starts from the previous model and changes one assumption, so we can see which extra flexibility is actually doing useful work.
M0 is the original STES benchmark. M1 is the constrained one-dimensional VolGRU written so that it should reproduce STES exactly under shared gate parameters. M2 keeps the STES gate but replaces the fixed candidate x_t with a learned positive linear candidate. M3 lets the update gate depend on the current state as well as the observable features. M4 adds reset gating. M5 replaces the linear candidate with a small nonlinear positive candidate, giving the full VolGRU specification studied here.
So the point of the comparison is not to line up unrelated models under one table. It is to move from STES toward GRU one step at a time and ask which newly released assumption, if any, actually improves the forecast.
Fit M0 STES and XGBSTES baseline on Part-4 features
The constrained VolGRU in M1 should reproduce STES predictions and gates when the gate parameter vector is set equal to the STES estimate and candidate is fixed to x_t=r_t^2.
The first table reports model-level performance. The second table reports sequential changes along the STES-to-VolGRU ladder so that each relaxation can be assessed conditionally on the previous rung.
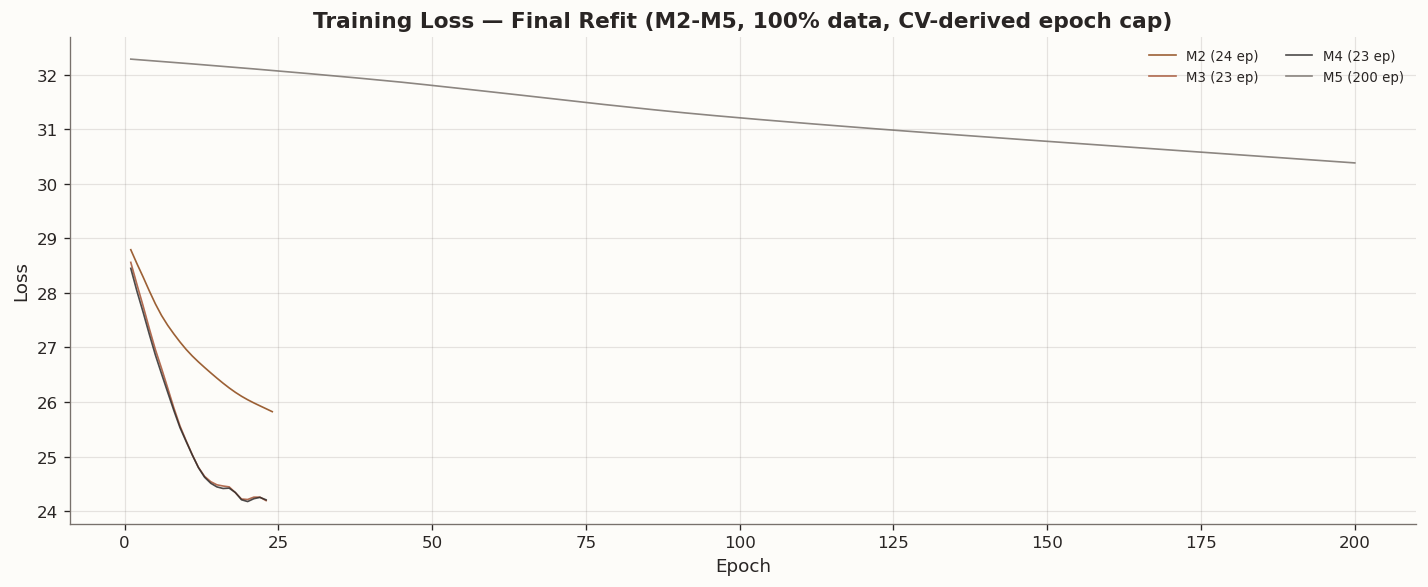
The scalar ladder makes it fairly easy to see which relaxations add something and which mostly just add flexibility. All models were tuned with the same three-fold time-series CV protocol. In each fold, val_fraction=0.15 determines both the best regularization setting and the average stopping epoch. The final refit then uses 100% of the training data with val_fraction=0.0, capped at the CV-derived epoch limit, so the final comparison keeps the same data visibility as STES.
Candidate relaxation (M2). Replacing the hard-coded candidate \tilde{h}_t = r_t^2 with a learnable linear positive transformation is the first scalar relaxation that clearly matters. CV again selects the strongest regularization tier (weight_decay=0.01, beta_stay_close_lambda=0.05, gate_entropy_lambda=0.01) and caps the refit at 24 epochs. M2 is the best-performing trainable VolGRU rung by RMSE, with OS RMSE = 0.000461 versus STES at 0.000473. But the gain is narrow and it comes with much worse proportional calibration: OS QLIKE rises to 1.80 from STES’s 1.62.
State-dependent gating (M3). Letting the update gate observe the current scalar state adds a feedback loop that helps mainly under QLIKE. M3 reduces OS QLIKE from 1.80 to 1.76 relative to M2, and the DM test confirms that improvement is statistically significant under QLIKE (DM = -4.30, p < 0.001). But the same relaxation gives back the RMSE gain: OS RMSE widens to 0.000483. So state dependence helps distributional calibration relative to M2, but it still does not recover the STES benchmark under either loss.
Reset gate (M4). Adding a reset gate changes very little in a one-dimensional state space. M4 lands at OS RMSE = 0.000478 and OS QLIKE = 1.77, nearly identical to M3. In this scalar setting, the reset mechanism is mostly inert.
MLP candidate (M5). The nonlinear candidate is the most expressive specification in the scalar ladder, but it is also clearly the weakest rung. The refit runs for the full 200-epoch cap and ends at OS RMSE = 0.000524 and OS QLIKE = 1.85. The DM comparison against STES is insignificant under squared error (p = 0.15) but significantly worse under QLIKE (p = 0.004), so the richer candidate does not buy useful forecast flexibility in this single-asset setup.
SE vs QLIKE divergence. The tension between RMSE and QLIKE is sharp. M2 improves RMSE relative to STES while materially worsening QLIKE, and M3 partially repairs QLIKE relative to M2 while giving back the RMSE gain. The broader message is the same as in Part 4: the MSE training objective rewards point-forecast accuracy in variance levels, whereas QLIKE is more sensitive to proportional miscalibration. STES remains the strongest model in the scalar ladder by QLIKE, while XGBSTES remains the overall RMSE leader with OS RMSE = 0.000444.
Training protocol. The two-phase protocol matters because it removes the main apples-to-oranges objection. Scalar VolGRU sees the same augmented feature matrix and the same full training window during the final fit, so any remaining performance gap is about model structure rather than data visibility.
13 Conclusion
The constrained VolGRU specification reproduces STES exactly under shared gate coefficients, so STES really is a strict special case of the one-dimensional VolGRU formulation studied here. Once that equivalence is in place, the scalar relaxation ladder reveals a clear split by loss function rather than a clear overall winner. The best trainable VolGRU rung by squared error is M2, with OS RMSE = 0.000461 versus 0.000473 for STES, but its OS QLIKE deteriorates sharply to 1.80. The best VolGRU rung by QLIKE is M3, which improves on M2 but still reaches only 1.76, well above STES at 1.62. The full nonlinear endpoint M5 is worse still, with OS RMSE = 0.000524 and OS QLIKE = 1.85.
The DM tests sharpen that picture. M3 and M4 are significantly better than M2 under QLIKE, but none of the trainable scalar VolGRU variants significantly improves on STES under squared-error loss. M5 is significantly worse than STES under QLIKE. Meanwhile, the benchmark XGBSTES model remains the strongest point-forecast competitor overall with OS RMSE = 0.000444, though it too trails STES on QLIKE.
So the main takeaway is not that VolGRU dominates STES. It is that relaxing STES within a one-dimensional hidden state does create useful flexibility, but the benefits are criterion-specific: a mild candidate relaxation can help RMSE, while state-dependent gating helps repair some of the QLIKE damage that follows. None of the tested scalar relaxations dominates the STES benchmark across both loss functions.
That leaves a natural next step. Part 7 will ask what changes when the latent state is no longer forced to be scalar. In other words, if Part 6 studies STES as a constrained one-dimensional GRU, the next post studies what becomes possible once VolGRU is allowed to keep a genuinely multi-dimensional hidden state.