Volatility Forecasts (Part 4 — RMSE Benchmarks and QLIKE Training)
2026-03-03
1 Introduction
In Part 3 we showed that replacing the fixed smoothing coefficient in exponential smoothing with a learned gate improves one-step-ahead volatility forecasts. The best model in that post was XGBSTES, where the gate is learned by a gradient-boosted linear model rather than a single logistic regression. Every result so far has been trained and scored under RMSE, following the paper from Part 1 (Liu, Taylor & Choo, 2020).
Before adding new covariates, we want to settle a more basic modeling choice: what loss function should train the model? RMSE is a common choice for forecasting task in general, but for variance forecasts the more natural objective is often QLIKE.
The case for QLIKE rests on two properties established in the forecast-evaluation literature. First, Patton (2011) showed that QLIKE belongs to the class of loss functions that are robust to noise in the volatility proxy — it ranks forecasts consistently even when realized variance is measured with error. Second, Hansen and Lunde (2005) demonstrated that QLIKE provides a consistent ranking function for conditional-variance models, meaning the best forecast under the population criterion wins in large samples regardless of the proxy used.
Practically, the difference matters because RMSE is level-sensitive: a few large volatility spikes dominate the score. QLIKE evaluates forecasts proportionally, so it is more informative about whether the model is systematically too high or too low as a variance forecast, not just whether it tracks large episodes in absolute magnitude. A model can look strong under RMSE by following big moves, yet score poorly under QLIKE because it is miscalibrated on a proportional basis. Rather than choosing one metric by convention, this post compares both directly.
The questions are:
Do the MSE-trained models still compare well on the fixed split from the earlier posts?
What changes when we retrain each model family under QLIKE, keeping the same features and split?
Do MSE and QLIKE lead to different out-of-sample rankings or calibration judgments?
We keep the same SPY sample spanning January 2000 through December 2023. As in Part 3, we use the first 200 observations as warm-up, use observations 201 through 4,000 for estimation, and reserve the remainder for out-of-sample evaluation. The target remains next-day squared return. The scope of this post is limited to the QLIKE loss-function question. We derive the QLIKE gradient for STES, show how it enters the XGBSTES custom objective, and compare all seven model variants empirically. Regularization and feature expansion are deferred to Part 5.
2 Methodology: Same Models, Different Training Objectives
2.1 Model inventory
We compare four baseline architectures on the same fixed split. Let y_{t+1} = r_{t+1}^2 denote next-day realized variance and let \hat v_{t+1 \vert t} denote the one-step-ahead forecast formed at time t.
GARCH(1,1): the standard parametric conditional-variance benchmark fit by maximum likelihood.
ES: exponential smoothing with a fixed coefficient.
STES: smooth-transition exponential smoothing with a logistic gate \alpha_t = \sigma(x_t^\top \beta).
XGBSTES: the same smoothing recursion, but with the gate produced by a boosted linear model f_{\text{XGB}}(x_t).
The feature set stays fixed throughout this post. Every STES and XGBSTES model uses the same three return-based inputs from Part 3 — lagged return, lagged absolute return, and lagged squared return. The only thing that changes is the training objective.
2.2 Two training objectives
To make the comparison fair, we train every model under both RMSE and QLIKE where possible. ES, STES, and XGBSTES each appear twice — once trained under squared error, once under QLIKE. That gives us six model–loss variants, plus GARCH.
GARCH is already QLIKE-trained. As the appendix shows, GARCH’s Gaussian MLE objective is mathematically equivalent to the QLIKE loss — the two produce exactly the same parameter estimates. GARCH therefore naturally sits on the QLIKE side of the comparison. We keep it as a single MLE-fitted model, giving us seven model variants in total.
2.3 The QLIKE objective
For a variance forecast \hat v_{t+1|t}(\theta), the per-observation QLIKE loss is
The appendix derives this loss from the Gaussian log-likelihood used to fit GARCH(1,1). In brief: maximizing the conditional log-likelihood of a Gaussian variance model is equivalent to minimizing \sum_t [\log \hat v_t + y_t / \hat v_t], and the per-observation QLIKE above is just this expression shifted by the constants -\log y_t - 1 so that \ell = 0 when \hat v_{t+1|t} = y_{t+1} exactly.
The “quasi” in QLIKE means the Gaussian distributional assumption need not hold. Patton (2011) showed that QLIKE ranks forecasts consistently even when the true return distribution is non-Gaussian, as long as the conditional mean of y_{t+1} equals the forecast target. That robustness is what makes it attractive for variance models, where the Gaussian assumption is routinely violated.
The training objective sums this over the estimation sample:
Both STES and XGBSTES use light L2 regularization in this post. For STES, we select the L2 penalty from a small grid via three-fold cross-validation. For XGBSTES, XGBoost’s built-in reg_lambda provides the same role. This keeps the gate weights from drifting too far; the heavier regularization machinery — adaptive lasso and elastic net — arrives in Part 5 once we expand the feature set.
For ES, we simply fit an STESModel with a constant-only feature under loss="qlike", which reduces the logistic gate to a single optimized smoothing coefficient. For STES, \theta = \beta enters through the logistic gate. For XGBSTES, the gate is still learned end-to-end, but the boosted linear weights are chosen to minimize the same QLIKE target rather than squared error. The sections below derive the gradients that make this possible.
3 QLIKE Gradient and the STES Jacobian
This section derives the gradient that lets us train STES under QLIKE using scipy.optimize.minimize with L-BFGS-B. The derivation parallels the RMSE Jacobian from Part 3, and the same sensitivity recursion applies — the only thing that changes is how the loss couples to the forecast.
This is the key quantity. When \hat v > y_{t+1} the gradient is positive (the forecast is too high, push it down); when \hat v < y_{t+1} it is negative (push it up). The \hat v^2 denominator makes the gradient automatically scale-aware — small forecasts receive proportionally stronger corrections than large ones. Compare this with the RMSE gradient \partial \ell^{\text{MSE}}_t / \partial \hat v = 2(\hat v - y_{t+1}), which treats all forecast levels equally.
The second factor, \partial \hat v_{t+1|t} / \partial \beta_j, is the sensitivity of the forecast to each gate parameter. It does not depend on the choice of loss and is purely a property of the STES recursion.
3.3 Step 3: Forward sensitivity recursion
Instead of differentiating the loss end-to-end in one pass, we separate the calculation into a forward recursion that propagates parameter sensitivities through the STES state, and a backward weighting that multiplies those sensitivities by the per-step loss gradient. The forward pass computes how each parameter nudges the forecast at every time step; the backward weighting (Step 1) tells us how much that nudge costs. This two-part structure is the same idea behind backpropagation in neural networks — we reuse the forward sensitivities for any choice of loss, and only swap the backward weights when we switch from RMSE to QLIKE.
In Part 3 we derived the forward-mode recursion for this sensitivity. Defining D_{t+1,j} = \partial \hat v_{t+1|t} / \partial \beta_j, the recursion is
This is a scalar objective with an analytical gradient vector, so we pass it to scipy.optimize.minimize with the L-BFGS-B solver. This is the main structural difference from RMSE training: the RMSE path uses scipy.optimize.least_squares, which exploits the vector of residuals and the Jacobian matrix [D_{t+1,j}]_{t,j} for Gauss-Newton steps. QLIKE cannot be decomposed into a sum of squared residuals, so we fall back to the general-purpose L-BFGS-B optimizer that only needs the scalar loss and its gradient.
4 XGBSTES with QLIKE Training
Switching XGBSTES from RMSE to QLIKE requires supplying XGBoost with a custom objective that returns per-leaf gradient and Hessian-diagonal values on the QLIKE scale. The end-to-end sensitivity backward pass from Part 3 carries over unchanged — only the top-level loss derivatives are different.
4.1 Custom gradient and Hessian
XGBoost’s custom-objective interface expects, for each observation t, a gradient g_t and a Hessian diagonal h_t of the loss with respect to the model’s raw prediction. For QLIKE these are:
The gradient g_t is the same expression derived in the previous section. The Hessian diagonal h_t follows from differentiating g_t once more with respect to \hat v_{t+1|t}:
Note that h_t can be negative when \hat v > 2y (i.e., the forecast is more than twice the realized variance). XGBoost handles this gracefully in the boosted-linear setting by regularizing the leaf weights.
4.2 End-to-end backward pass
In the end-to-end training mode, the STES recursion sits between XGBoost’s raw gate output and the final variance forecast. The backward pass propagates g_t and h_t through the sensitivity recursion to compute the gradient with respect to the boosted-linear gate parameters. This is the same forward-backward structure used for RMSE in Part 3 — the only change is that g_t and h_t are now computed from QLIKE rather than squared error. In practice, switching from RMSE to QLIKE training is a one-line change: set loss="qlike" in the model constructor.
actual_is = y_tr.valuesactual_os = y_te.valuescomparison_table = pd.DataFrame( {"Model": list(model_predictions.keys()),"Train Loss": [model_predictions[name]["train_loss"] for name in model_predictions],"IS RMSE": [rmse(actual_is, model_predictions[name]["is"]) for name in model_predictions],"OS RMSE": [rmse(actual_os, model_predictions[name]["os"]) for name in model_predictions],"OS MAE": [mae(actual_os, model_predictions[name]["os"]) for name in model_predictions],"OS QLIKE": [qlike(actual_os, model_predictions[name]["os"]) for name in model_predictions], })display(style_results_table(comparison_table, precision=6, index_col="Model"))
All seven model variants: GARCH baseline, MSE-trained, and QLIKE-trained
Head-to-head: MSE-trained vs QLIKE-trained within each family:
OS RMSE (MSE train)
OS RMSE (QLIKE train)
Delta RMSE
OS QLIKE (MSE train)
OS QLIKE (QLIKE train)
Delta QLIKE
Family
ES
0.000464
0.000477
0.000013
1.619823
1.613638
-0.006186
STES
0.000451
0.000478
0.000027
1.637744
1.599050
-0.038694
XGBSTES
0.000443
0.000472
0.000029
1.685679
1.610119
-0.075559
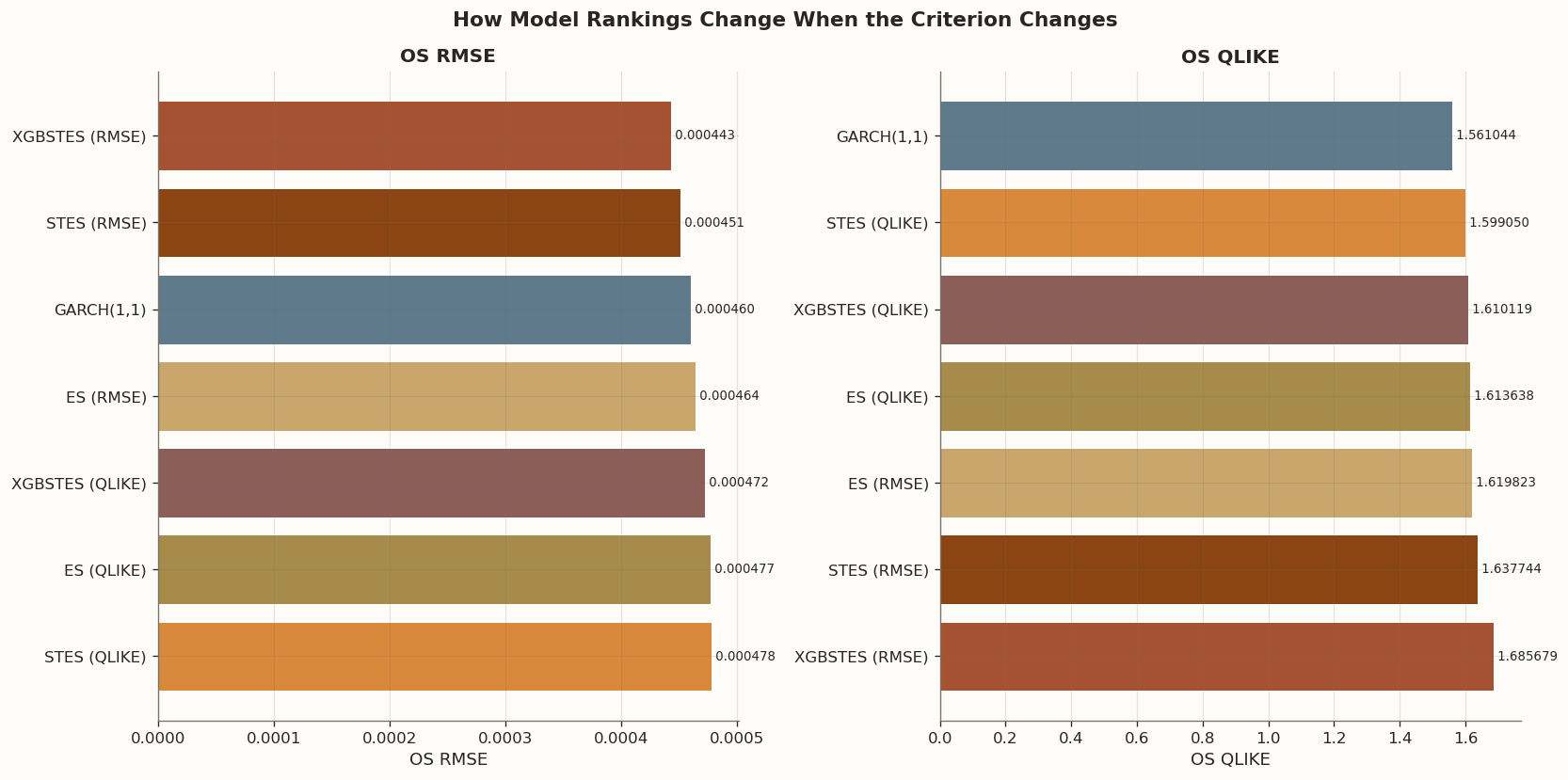
Out-of-sample ranking under the two loss functions:
OS RMSE
OS QLIKE
RMSE Rank
QLIKE Rank
Model
XGBSTES (RMSE)
0.000443
1.685679
1.000000
7.000000
STES (RMSE)
0.000451
1.637744
2.000000
6.000000
GARCH(1,1)
0.000460
1.561044
3.000000
1.000000
ES (RMSE)
0.000464
1.619823
4.000000
5.000000
XGBSTES (QLIKE)
0.000472
1.610119
5.000000
3.000000
ES (QLIKE)
0.000477
1.613638
6.000000
4.000000
STES (QLIKE)
0.000478
1.599050
7.000000
2.000000
Head-to-head comparison: MSE-trained vs QLIKE-trained within each model family
5 Formal Comparison and Calibration
Point metrics are informative, but the interesting question is whether the loss swap changes the forecast in a statistically meaningful way or merely nudges the ranking table. We therefore look at two complementary diagnostics. Our post on forecast comparison provides some background on these two diagnostics.
Diebold-Mariano tests on squared error and QLIKE loss differentials. For the pairwise comparisons below, a negative statistic favors the first-named model.
Mincer-Zarnowitz regressions on the variance scale. Here a slope close to one is the practical calibration target.
DM tests and Mincer-Zarnowitz regressions for MSE-trained vs QLIKE-trained models
The DM tests split the three model families into two groups:
ES and STES — no significant difference. For both families, switching to QLIKE training nudges the QLIKE score downward (ES: −0.006; STES: −0.039) and RMSE upward by a tiny amount, but none of these differences reach statistical significance (DM p-values all above 0.16). The exponential-smoothing recursion naturally produces strictly positive variance forecasts, so QLIKE training is well-posed — the gains are simply small.
XGBSTES — significant QLIKE improvement. XGBSTES is the only family where QLIKE training yields a statistically significant gain: the QLIKE score drops by 0.076 (DM = −2.57, p = 0.01). The RMSE penalty is marginal (DM = 1.85, p = 0.065). Cross-family, GARCH significantly beats XGBSTES (RMSE) on QLIKE (DM = 2.49, p = 0.013); retraining XGBSTES under QLIKE narrows the gap but does not quite close it (p = 0.069).
The MZ regressions confirm the ranking chart’s underlying story. STES (RMSE) and GARCH are the best-calibrated models (β ≈ 1.01 and 1.02 respectively) — both sit close to the ideal β = 1 line. XGBSTES (RMSE) has the highest R² (0.32) but overshoots slightly (β = 1.07). QLIKE training tends to push calibration away from one: STES (QLIKE) overshoots to β = 1.52, while XGBSTES (QLIKE) undershoots to β = 0.73. The trade-off is real: optimizing for QLIKE improves QLIKE scores at the cost of MZ calibration and RMSE.
6 Ranking the Models Under Both Criteria
The figure below makes the trade-off visible. The left panel orders all seven models by out-of-sample RMSE; the right panel orders the same forecasts by out-of-sample QLIKE. Two things jump out:
RMSE-trained models sweep the top of the RMSE panel. XGBSTES (RMSE) leads, followed by STES (RMSE), GARCH, and ES (RMSE). Every QLIKE-trained variant ranks below its RMSE counterpart on this axis.
GARCH is the only model in the top three on both panels — 3rd in RMSE, 1st in QLIKE. Its MLE objective, mathematically equivalent to QLIKE, gives it a natural dual advantage.
Running seven model variants through a symmetric training experiment — each family fitted under both RMSE and QLIKE wherever feasible — produces two clear take-aways:
The training loss reshuffles rankings, but only within the metric it targets. Under RMSE, the top three models are all RMSE-trained; under QLIKE, the top three are all QLIKE-aligned (GARCH MLE, STES QLIKE, XGBSTES QLIKE). No single model dominates both lists, confirming that the loss function is a design choice that trades accuracy on one criterion for accuracy on the other.
GARCH’s MLE is already QLIKE, and it shows. GARCH(1,1) is the only model that lands in the top three under both criteria (3rd in RMSE, 1st in QLIKE). There is no separate “QLIKE-trained GARCH” because MLE already minimizes QLIKE for a Gaussian likelihood; this structural advantage makes GARCH a strong default when the practitioner’s criterion is uncertain.
The experiment also reveals what it leaves unanswered. All models here use the same three gate features (constant, return, realized variance) and a single in-sample/out-of-sample split. Whether richer feature sets or more sophisticated time-series cross-validation would change the rankings is the subject of Part 5.
7.1 What’s next
We will tackle the following things in the next few posts.
Feature expansion — adding trailing realized-variance windows, calendar and event indicators, and CFTC positioning data to the gate inputs.
Regularization — deriving and implementing adaptive lasso and elastic net for the STES gate under both RMSE (coordinate descent) and QLIKE (proximal L-BFGS), so we can expand the feature set without overfitting.
Train/test split — comparing model performance using more sophisticated time-series splits to create real-time variance forecasts and DM statistics.
8 Appendix: GARCH(1,1) Model Recap and MLE
We quickly give a self-contained recap of the GARCH(1,1) model and derive its maximum-likelihood estimator step by step. The aim is to show that GARCH MLE is mathematically equivalent to QLIKE, a statement we made above.
8.1 The model
GARCH(1,1) (Bollerslev, 1986) specifies a conditionally Gaussian return process:
The three parameters (\omega, \alpha, \beta) are constrained to \omega > 0, \alpha \ge 0, \beta \ge 0 to keep the variance positive, and \alpha + \beta < 1 for covariance stationarity. The unconditional variance is \bar\sigma^2 = \omega / (1 - \alpha - \beta).
Intuitively, the recursion says: today’s variance is a weighted combination of a long-run baseline (\omega), yesterday’s squared return (\alpha r_{t-1}^2, the “shock” component), and yesterday’s conditional variance (\beta \sigma_{t-1}^2, the “persistence” component). When \beta is large — typically 0.85–0.95 for daily equity returns — variance shocks decay slowly, which captures the well-known volatility clustering in financial returns.
8.2 Maximum likelihood estimation
GARCH parameters are fit by maximum likelihood. Given a sample of returns (r_1, \ldots, r_T) and an initial variance \sigma_1^2 (usually set to the sample variance), each observation has the conditional density
Now identify the GARCH forecast with the generic variance forecast: \hat v_t = \sigma_t^2, and the squared return with the realized-variance proxy: y_t = r_t^2. The MLE objective becomes
The two expressions differ only by -\log y_t - 1, which is constant with respect to (\omega, \alpha, \beta). Maximizing the Gaussian log-likelihood and minimizing QLIKE produce exactly the same parameter estimates.
This equivalence is by design — QLIKE is the evaluation counterpart of the Gaussian quasi-likelihood. The result holds even when returns are non-Gaussian, because the Gaussian log-likelihood is a proper quasi-likelihood for the conditional variance: its first-order conditions are unbiased under any distribution with the correct conditional mean and variance (Bollerslev and Wooldridge, 1992). That robustness is what makes MLE the default fitting procedure for GARCH in practice, and what makes QLIKE the natural evaluation metric for variance forecasts.
8.4 Why not fit GARCH under MSE?
One could in principle fit GARCH under MSE instead — minimizing \sum_t (r_t^2 - \sigma_t^2)^2 over the recursion parameters. This is sometimes called LS-GARCH (least-squares GARCH), though it is non-standard for good reason. MSE treats all observations equally in absolute terms, so a few large volatility spikes dominate the loss surface and can distort parameter estimates. MLE under the Gaussian quasi-likelihood is more statistically efficient: it weights each observation proportionally to its variance, which is the natural scale for a variance model. The arch package — and nearly all GARCH implementations in practice — fits by MLE only.